Security operations cannot rely on static rules forever. Attackers adapt, environments change, and heuristic playbooks that worked last quarter become tomorrow's false-positive factory. Dolutech SOC Model V1 is designed to improve continuously — but not by letting an autonomous model experiment on live incident decisions. Instead, it uses a human-in-the-loop (HITL) learning architecture: active learning guided by analyst feedback, encoded as supervised ground-truth labels, and fed back into model refinement through a controlled data flywheel.
This article explains how that architecture works, why we chose supervised active learning over high-risk reinforcement learning in production, and what it means for operators who need both speed and accountability.
The problem with static SOCs
Traditional SOCs depend on fixed signatures, rigid correlation rules, and manually maintained playbooks. Each layer helps — until threat actors shift tactics, cloud estates grow, or alert volume crosses the threshold where analysts stop reading context. The result is familiar: alert fatigue, slower mean time to respond, and a widening gap between what the SOC detects and what it understands.
Heuristic systems do not learn from their mistakes in a structured way. They require constant human maintenance just to stay level, not to get better. That maintenance cost scales poorly for SMEs and MSSPs who cannot staff a 24/7 tuning team.
Design rationale: active learning, not autonomous trial-and-error
Reinforcement learning that explores actions in live security environments is seductive on paper and dangerous in practice. A wrong remediation, a misclassified breach, or an automated block on critical infrastructure can cause more damage than the original alert.
Our approach prioritizes supervised active learning inside a governed pipeline:
- Analyst feedback becomes labels — human validation on high-stakes or ambiguous decisions produces ground truth the model can learn from.
- Deterministic screening first — known-bad patterns and policy gates run before probabilistic AI reasoning, reducing the attack surface for model errors.
- Fail-safe escalation — when confidence is low or impact is high, the workflow routes to humans instead of silent automation.
- Auditability by design — every stage from ingestion to refinement is traceable for compliance and post-incident review.
The model gets sharper over time because real analysts correct real decisions — not because it randomly probes production.
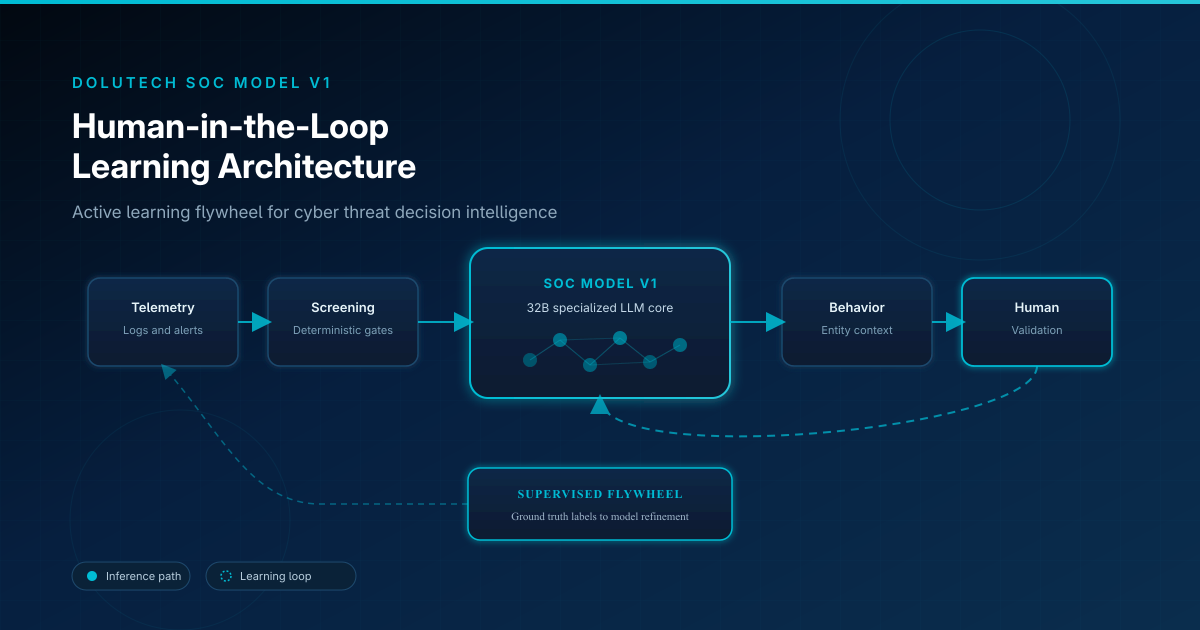
Decision workflow: six stages
Inside SOC AI Agent, threat intelligence flows through a repeatable decision pipeline powered by SOC Model V1:
- Telemetry ingestion — logs, alerts, and contextual signals from the customer environment enter the platform.
- Deterministic screening — policy rules, known IOCs, and hard gates filter noise and enforce non-negotiable constraints.
- AI contextual analysis — SOC Model V1 interprets remaining events with domain-specific reasoning trained on curated security data.
- Behavioral evaluation — entity and session behavior is assessed against baselines and cross-signal correlation.
- Human validation — analysts review escalations, confirm or correct conclusions, and approve sensitive actions when required.
- Model refinement — validated outcomes feed the supervised learning flywheel for the next training cycle.
Stages 1–4 deliver speed at scale. Stage 5 ensures accountability where it matters. Stage 6 compounds capability across deployments.
How the model learns
Learning is not a one-time training event. It is a closed loop:
Production event → AI recommendation → human validation → ground-truth label → curated dataset → supervised refinement → improved inference on the next event.
Human experts are not a bottleneck bolted onto automation — they are the quality gate that converts operational judgment into training signal. Preference pairs from triage decisions feed alignment (DPO); validated incident narratives enrich SFT corpora; production feedback through SOC AI Agent informs continuous RL — always within governance boundaries, never as unchecked autonomous experimentation on customer environments.
This is the difference between a model that sounds confident and one that becomes more accurate on the work your analysts actually perform.
Safety and governance
Adaptive AI in security must earn trust operationally, not just in benchmarks. Our architecture embeds:
- Full audit trails — who approved what, when, and on which evidence.
- Tiered autonomy — automatic response where risk is low; human gates where impact is high.
- Data redaction and consent boundaries — customer production data is not absorbed into training without explicit agreement.
- Escalation defaults — uncertainty routes up, not sideways into silent failure.
These controls are not afterthoughts. They are structural requirements for any system that learns from live security work.
Traditional SOC vs adaptive learning
| Dimension | Traditional / static SOC | Dolutech adaptive HITL |
|---|---|---|
| Rule maintenance | Manual, continuous tuning | Model refinement from validated feedback |
| False positives | Accumulate as environments drift | Active learning targets recurring noise patterns |
| Analyst role | Reactive ticket processing | Quality gate + label generation for improvement |
| Learning mechanism | None (or ad-hoc playbook edits) | Supervised flywheel with human ground truth |
| Risk profile | Missed threats from stale rules | Governed autonomy with fail-safe escalation |
| Competitive moat | Commodity tooling | Compounding decision intelligence per deployment |
What this means for operators
- Less alert fatigue over time — the system learns which patterns your analysts dismiss and which they escalate.
- Faster triage without blind automation — AI handles volume; humans retain authority on consequential calls.
- Defensible decisions — audit-ready workflows for regulators, insurers, and internal risk committees.
- A model that matches your environment — not a generic chat wrapper, but a specialization loop tied to real SOC work.
Further reading
- Why a specialized LLM beats general models for SOC work
- MDR with human-in-the-loop — without building an internal SOC
- Dolutech SOC Model V1 — request early API access
- SOC AI Agent — autonomous operations platform
Full architecture paper
Download the complete technical document on Dolutech SOC Model V1 — decision workflow, safety controls, and the supervised learning flywheel (PDF, English).


