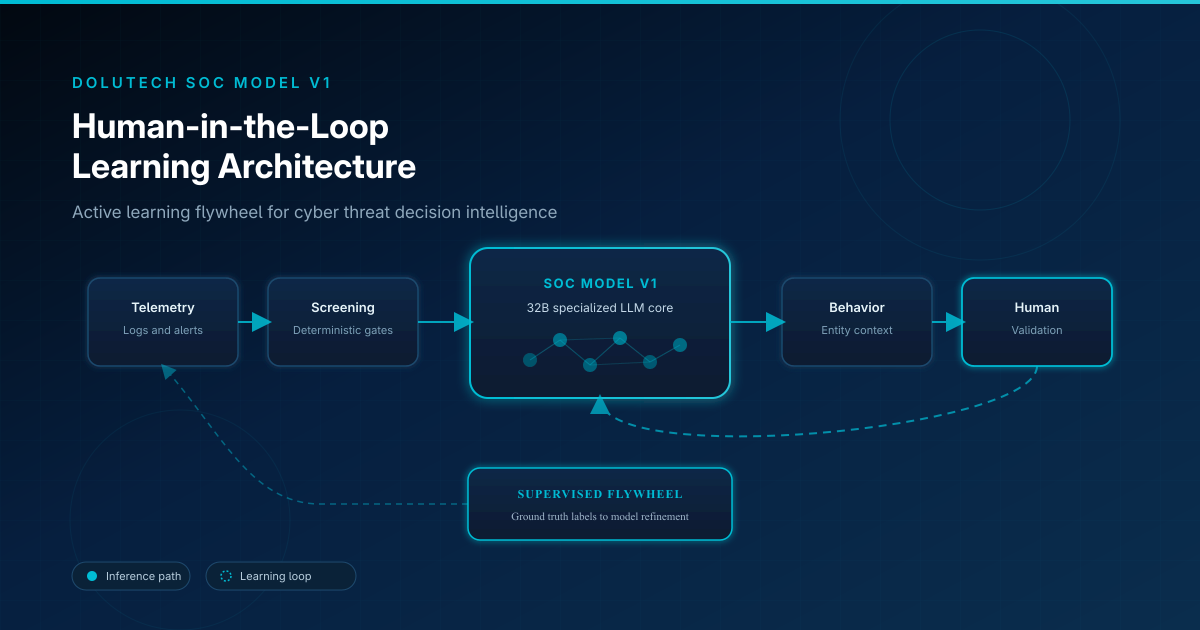
Las operaciones de seguridad no pueden depender de reglas estáticas para siempre. Los atacantes se adaptan, los entornos cambian y los playbooks heurísticos se convierten en la fábrica de falsos positivos de mañana. Dolutech SOC Model V1 está diseñado para mejorar continuamente — pero no dejando que un modelo autónomo experimente con decisiones de incidentes en producción. En su lugar, usa una arquitectura de aprendizaje human-in-the-loop (HITL): active learning guiado por feedback de analistas, codificado como etiquetas supervisadas de ground truth, y devuelto al refinamiento del modelo mediante un flywheel de datos controlado.
El problema de los SOC estáticos
Los SOC tradicionales dependen de firmas fijas, reglas de correlación rígidas y playbooks mantenidos manualmente. El resultado es familiar: fatiga de alertas, MTTR más lento y una brecha creciente entre lo que el SOC detecta y lo que comprende.
Racional de diseño: active learning, no trial-and-error autónomo
El reinforcement learning que explora acciones en entornos de seguridad reales es seductor en papel y peligroso en la práctica. Nuestro enfoque prioriza el active learning supervisado en un pipeline gobernado:
- El feedback del analista se convierte en etiquetas
- Cribado determinista primero
- Escalado fail-safe
- Auditabilidad por diseño
Flujo de decisión: seis etapas
En SOC AI Agent, la inteligencia de amenazas recorre un pipeline repetible impulsado por SOC Model V1:
- Ingesta de telemetría
- Cribado determinista
- Análisis contextual con IA
- Evaluación conductual
- Validación humana
- Refinamiento del modelo
Cómo aprende el modelo
Evento de producción → recomendación de IA → validación humana → etiqueta ground truth → dataset curado → refinamiento supervisado → inferencia mejorada en el siguiente evento.
Los expertos humanos son la puerta de calidad que convierte el juicio operativo en señal de entrenamiento.
Seguridad y gobernanza
- Auditoría completa
- Autonomía por capas
- Redacción de datos y consentimiento
- Escalado por defecto ante incertidumbre
SOC tradicional vs aprendizaje adaptativo
| Dimensión | SOC tradicional / estático | HITL adaptativo Dolutech |
|---|---|---|
| Mantenimiento de reglas | Ajuste manual continuo | Refinamiento del modelo desde feedback validado |
| Falsos positivos | Se acumulan con la deriva del entorno | Active learning ataca patrones de ruido recurrentes |
| Rol del analista | Procesamiento reactivo de tickets | Puerta de calidad + generación de etiquetas |
| Mecanismo de aprendizaje | Ninguno (o ediciones ad-hoc) | Flywheel supervisado con ground truth humano |
| Perfil de riesgo | Amenazas perdidas por reglas obsoletas | Autonomía gobernada con escalado fail-safe |
Qué significa para los operadores
- Menos fatiga de alertas con el tiempo
- Triaje más rápido sin automatización ciega
- Decisiones defendibles
- Un modelo alineado con su entorno
Lecturas relacionadas
- Por qué un LLM especializado supera a los modelos generalistas en trabajo SOC
- MDR con human-in-the-loop — sin construir un SOC interno
- Dolutech SOC Model V1 — solicitar acceso anticipado a la API
- SOC AI Agent — plataforma de operaciones autónomas
Documento de arquitectura completo
Descargue el documento técnico completo sobre Dolutech SOC Model V1 — flujo de decisión, controles de seguridad y flywheel de aprendizaje supervisado (PDF, inglés).


