Operações de segurança não podem depender de regras estáticas para sempre. Atacantes adaptam-se, ambientes mudam e playbooks heurísticos que funcionavam no trimestre passado tornam-se a fábrica de falsos positivos de amanhã. O Dolutech SOC Model V1 foi concebido para melhorar continuamente — mas não deixando um modelo autónomo experimentar decisões de incidentes em produção. Em vez disso, usa uma arquitetura de aprendizagem human-in-the-loop (HITL): active learning guiado por feedback de analistas, codificado como rótulos supervisionados de ground truth, e devolvido ao refinamento do modelo através de um flywheel de dados controlado.
Este artigo explica como essa arquitetura funciona, por que escolhemos active learning supervisionado em vez de reinforcement learning de alto risco em produção, e o que significa para operadores que precisam de velocidade e responsabilização.
O problema dos SOCs estáticos
SOCs tradicionais dependem de assinaturas fixas, regras de correlação rígidas e playbooks mantidos manualmente. Cada camada ajuda — até os atores de ameaça mudarem táticas, as estates cloud crescerem ou o volume de alertas ultrapassar o limite em que analistas deixam de ler contexto. O resultado é familiar: fadiga de alertas, MTTR mais lento e um fosso crescente entre o que o SOC deteta e o que compreende.
Sistemas heurísticos não aprendem estruturadamente com os erros. Exigem manutenção humana constante só para se manterem no mesmo nível, não para melhorar. Esse custo escala mal para PMEs e MSSPs sem equipa de tuning 24/7.
Racional de design: active learning, não trial-and-error autónomo
Reinforcement learning que explora ações em ambientes de segurança reais é sedutor no papel e perigoso na prática. Uma remediação errada, uma violação mal classificada ou um bloqueio automático em infraestrutura crítica pode causar mais dano do que o alerta original.
A nossa abordagem prioriza active learning supervisionado num pipeline governado:
- Feedback de analistas vira rótulos — validação humana em decisões ambíguas ou de alto risco produz ground truth para o modelo.
- Screening determinístico primeiro — padrões conhecidos e gates de política correm antes do raciocínio probabilístico da IA.
- Escalonamento fail-safe — confiança baixa ou impacto alto encaminha para humanos em vez de automação silenciosa.
- Auditabilidade por design — cada etapa, da ingestão ao refinamento, é rastreável.
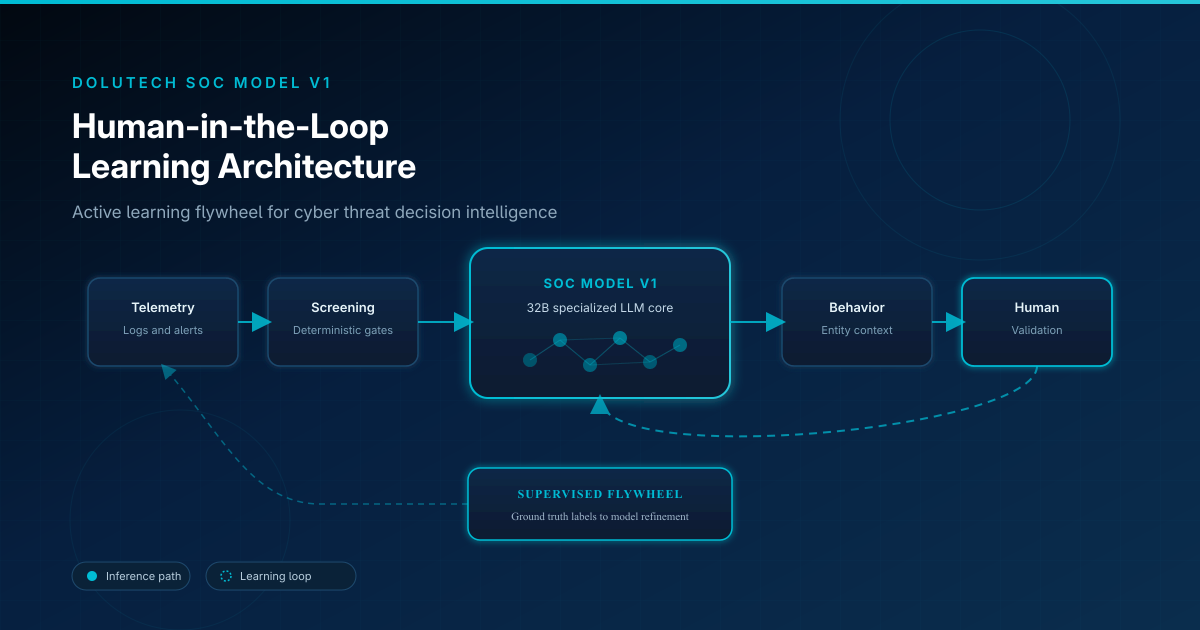
Fluxo de decisão: seis etapas
No SOC AI Agent, a inteligência de ameaças percorre um pipeline repetível alimentado pelo SOC Model V1:
- Ingestão de telemetria — logs, alertas e sinais contextuais do ambiente do cliente.
- Screening determinístico — regras de política, IOCs conhecidos e gates rígidos filtram ruído.
- Análise contextual por IA — SOC Model V1 interpreta eventos restantes com raciocínio de domínio.
- Avaliação comportamental — entidades e sessões avaliadas contra baselines e correlação cruzada.
- Validação humana — analistas revêm escalonamentos, confirmam ou corrigem conclusões.
- Refinamento do modelo — resultados validados alimentam o flywheel de aprendizagem supervisionada.
Como o modelo aprende
A aprendizagem não é um evento único de treino. É um ciclo fechado:
Evento de produção → recomendação da IA → validação humana → rótulo ground truth → dataset curado → refinamento supervisionado → inferência melhorada no evento seguinte.
Especialistas humanos não são um gargalo acoplado à automação — são o portão de qualidade que converte julgamento operacional em sinal de treino. Pares de preferência alimentam DPO; narrativas validadas enriquecem SFT; feedback de produção informa RL contínuo — sempre dentro de limites de governação.
Segurança e governação
- Trilhas de auditoria completas — quem aprovou o quê, quando e com que evidência.
- Autonomia em camadas — resposta automática onde o risco é baixo; gates humanos onde o impacto é alto.
- Redação de dados e consentimento — dados de produção do cliente não entram em treino sem acordo explícito.
- Defaults de escalonamento — incerteza sobe na hierarquia, não falha em silêncio.
SOC tradicional vs aprendizagem adaptativa
| Dimensão | SOC tradicional / estático | HITL adaptativo Dolutech |
|---|---|---|
| Manutenção de regras | Tuning manual contínuo | Refinamento do modelo a partir de feedback validado |
| Falsos positivos | Acumulam com deriva do ambiente | Active learning ataca padrões de ruído recorrentes |
| Papel do analista | Processamento reativo de tickets | Portão de qualidade + geração de rótulos |
| Mecanismo de aprendizagem | Nenhum (ou edições ad-hoc) | Flywheel supervisionado com ground truth humano |
| Perfil de risco | Ameaças perdidas por regras obsoletas | Autonomia governada com escalonamento fail-safe |
| Moat competitivo | Ferramentas commodity | Inteligência de decisão composta por deployment |
O que isto significa para operadores
- Menos fadiga de alertas ao longo do tempo — o sistema aprende o que analistas dispensam vs escalam.
- Triagem mais rápida sem automação cega — IA trata volume; humanos retêm autoridade em decisões consequentes.
- Decisões defensáveis — fluxos prontos para auditoria.
- Um modelo alinhado ao seu ambiente — não um wrapper de chat genérico.
Leitura adicional
- Por que um LLM especializado supera modelos generalistas em trabalho SOC
- MDR com human-in-the-loop — sem construir um SOC interno
- Dolutech SOC Model V1 — pedir acesso antecipado à API
- SOC AI Agent — plataforma de operações autónomas
Documento de arquitetura completo
Descarregue o documento técnico completo sobre o Dolutech SOC Model V1 — fluxo de decisão, controlos de segurança e flywheel de aprendizagem supervisionada (PDF, inglês).


