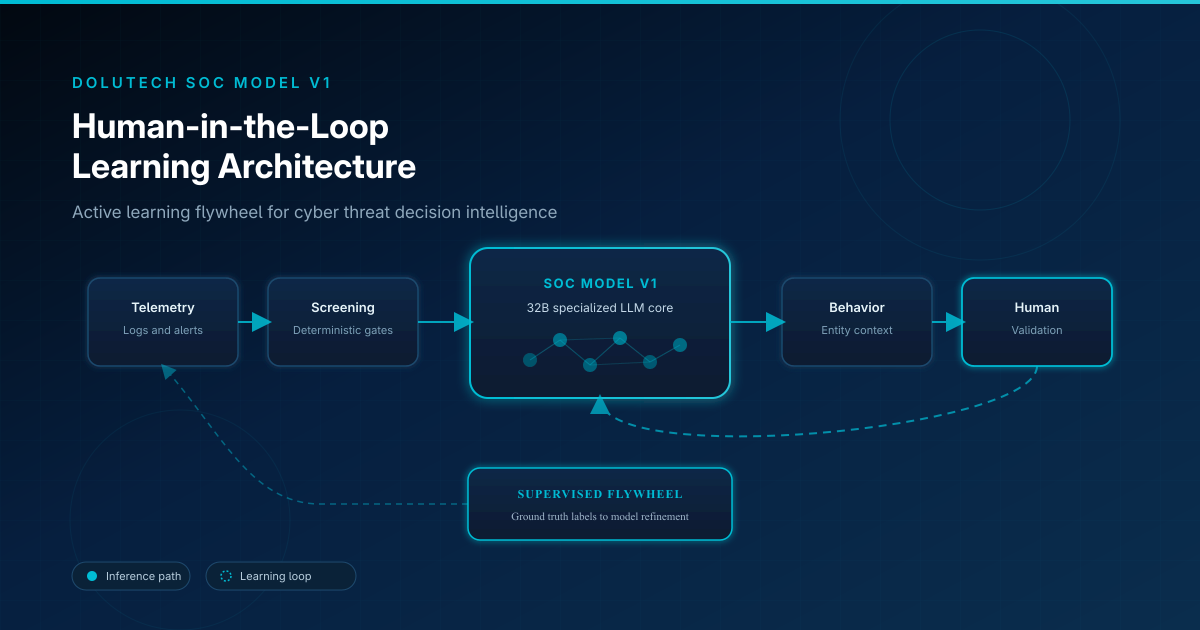
Sicherheitsoperationen können sich nicht ewig auf statische Regeln verlassen. Angreifer passen sich an, Umgebungen wachsen und heuristische Playbooks werden zur Falsch-Positiv-Fabrik von morgen. Dolutech SOC Model V1 ist für kontinuierliche Verbesserung gebaut — aber nicht, indem ein autonomes Modell live an Incident-Entscheidungen experimentiert. Stattdessen nutzt es eine Human-in-the-Loop (HITL)-Lernarchitektur: vom Analystenfeedback gesteuertes Active Learning, kodiert als überwachte Ground-Truth-Labels und über einen kontrollierten Daten-Flywheel zurück in die Modellverfeinerung.
Das Problem statischer SOCs
Traditionelle SOCs hängen von festen Signaturen, starren Korrelationsregeln und manuell gepflegten Playbooks ab. Das Ergebnis ist vertraut: Alert-Müdigkeit, langsamere Reaktionszeiten und eine wachsende Lücke zwischen Detektion und Verständnis.
Design-Rationale: Active Learning, kein autonomes Trial-and-Error
Reinforcement Learning, das in Live-Sicherheitsumgebungen Aktionen erkundet, ist auf dem Papier verlockend und in der Praxis gefährlich. Unser Ansatz priorisiert überwachtes Active Learning in einer governierten Pipeline:
- Analystenfeedback wird zu Labels
- Deterministisches Screening zuerst
- Fail-safe-Eskalation
- Auditierbarkeit by Design
Entscheidungsworkflow: sechs Stufen
In SOC AI Agent durchläuft Threat Intelligence eine wiederholbare Pipeline mit SOC Model V1:
- Telemetrie-Ingestion
- Deterministisches Screening
- KI-Kontextanalyse
- Verhaltensbewertung
- Menschliche Validierung
- Modellverfeinerung
Wie das Modell lernt
Produktionsereignis → KI-Empfehlung → menschliche Validierung → Ground-Truth-Label → kuratierter Datensatz → überwachte Verfeinerung → verbesserte Inferenz beim nächsten Ereignis.
Menschexperten sind das Qualitätsgate, das operatives Urteil in Trainingssignal umwandelt.
Sicherheit und Governance
- Vollständige Audit-Trails
- Gestufte Autonomie
- Datenredaktion und Einwilligung
- Eskalation bei Unsicherheit als Standard
Traditioneller SOC vs adaptives Lernen
| Dimension | Traditioneller / statischer SOC | Dolutech adaptives HITL |
|---|---|---|
| Regelwartung | Manuelles kontinuierliches Tuning | Modellverfeinerung aus validiertem Feedback |
| Falsch-Positive | Sammeln sich mit Umgebungsdrift | Active Learning zielt auf wiederkehrendes Rauschen |
| Analystenrolle | Reaktive Ticketbearbeitung | Qualitätsgate + Labelgenerierung |
| Lernmechanismus | Keiner (oder Ad-hoc-Edits) | Überwachter Flywheel mit menschlicher Ground Truth |
| Risikoprofil | Verpasste Bedrohungen durch veraltete Regeln | Governierte Autonomie mit Fail-safe-Eskalation |
Was das für Betreiber bedeutet
- Weniger Alert-Müdigkeit über die Zeit
- Schnellere Triage ohne blinde Automatisierung
- Verteidigbare Entscheidungen
- Ein Modell, das zu Ihrer Umgebung passt
Weiterführende Links
- Warum ein spezialisiertes LLM Generalmodelle im SOC schlägt
- MDR mit Human-in-the-Loop — ohne internes SOC
- Dolutech SOC Model V1 — frühen API-Zugang anfragen
- SOC AI Agent — autonome Betriebsplattform
Vollständiges Architekturpapier
Laden Sie das vollständige technische Dokument zu Dolutech SOC Model V1 herunter — Entscheidungsworkflow, Sicherheitskontrollen und überwachter Lern-Flywheel (PDF, Englisch).


