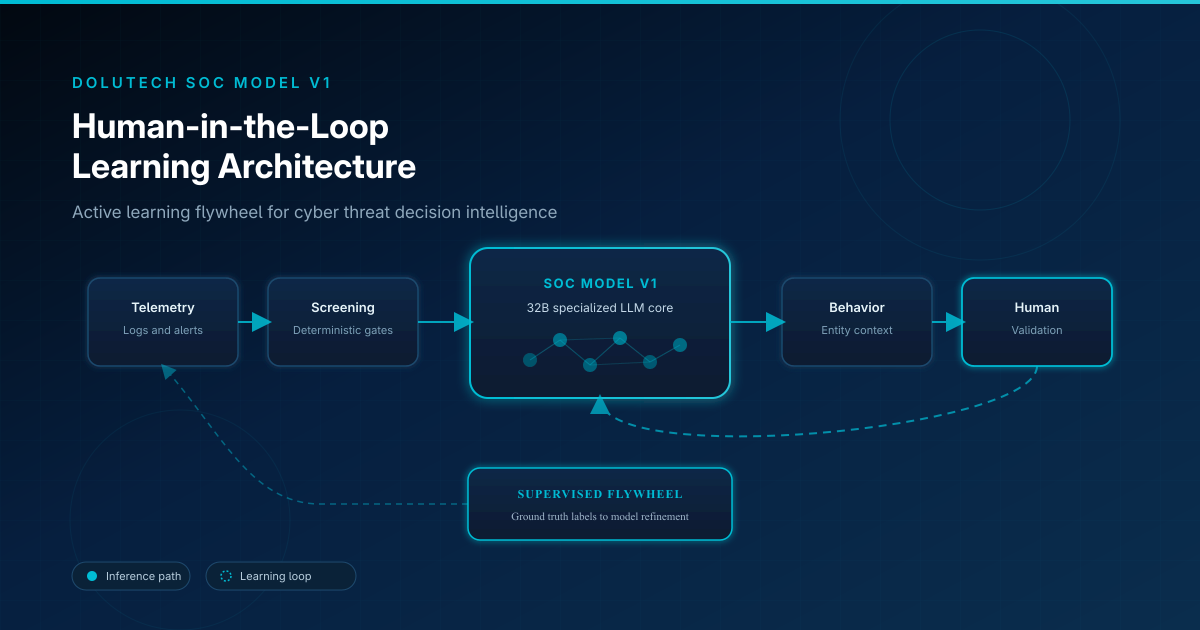
Les opérations de sécurité ne peuvent pas s'appuyer indéfiniment sur des règles statiques. Les attaquants s'adaptent, les environnements évoluent et les playbooks heuristiques deviennent la fabrique de faux positifs de demain. Dolutech SOC Model V1 est conçu pour s'améliorer en continu — mais pas en laissant un modèle autonome expérimenter sur des décisions d'incidents en production. Il utilise une architecture d'apprentissage human-in-the-loop (HITL) : active learning guidé par le feedback des analystes, encodé en labels supervisés de ground truth, réinjecté dans le raffinement du modèle via un flywheel de données contrôlé.
Le problème des SOC statiques
Les SOC traditionnels dépendent de signatures fixes, de règles de corrélation rigides et de playbooks maintenus manuellement. Résultat familier : fatigue d'alertes, MTTR plus lent et un fossé croissant entre détection et compréhension.
Rationale de conception : active learning, pas de trial-and-error autonome
Le reinforcement learning qui explore des actions en environnement de production est séduisant sur le papier et dangereux en pratique. Notre approche priorise l'active learning supervisé dans un pipeline gouverné :
- Le feedback analyste devient des labels
- Filtrage déterministe en premier
- Escalade fail-safe
- Auditabilité by design
Workflow de décision : six étapes
Dans SOC AI Agent, le renseignement sur les menaces suit un pipeline reproductible alimenté par SOC Model V1 :
- Ingestion de télémétrie
- Filtrage déterministe
- Analyse contextuelle IA
- Évaluation comportementale
- Validation humaine
- Raffinement du modèle
Comment le modèle apprend
Événement de production → recommandation IA → validation humaine → label ground truth → jeu de données curaté → raffinement supervisé → inférence améliorée sur l'événement suivant.
Les experts humains sont la porte qualité qui convertit le jugement opérationnel en signal d'entraînement.
Sécurité et gouvernance
- Pistes d'audit complètes
- Autonomie par niveaux
- Redaction des données et consentement
- Escalade par défaut en cas d'incertitude
SOC traditionnel vs apprentissage adaptatif
| Dimension | SOC traditionnel / statique | HITL adaptatif Dolutech |
|---|---|---|
| Maintenance des règles | Réglage manuel continu | Raffinement du modèle depuis feedback validé |
| Faux positifs | S'accumulent avec la dérive | Active learning cible le bruit récurrent |
| Rôle de l'analyste | Traitement réactif des tickets | Porte qualité + génération de labels |
| Mécanisme d'apprentissage | Aucun (ou edits ad-hoc) | Flywheel supervisé avec ground truth humain |
| Profil de risque | Menaces manquées par règles obsolètes | Autonomie gouvernée avec escalade fail-safe |
Ce que cela signifie pour les opérateurs
- Moins de fatigue d'alertes dans le temps
- Triage plus rapide sans automatisation aveugle
- Décisions défendables
- Un modèle aligné sur votre environnement
Pour aller plus loin
- Pourquoi un LLM spécialisé bat les modèles généralistes pour le travail SOC
- MDR avec human-in-the-loop — sans construire un SOC interne
- Dolutech SOC Model V1 — demander un accès anticipé à l'API
- SOC AI Agent — plateforme d'opérations autonomes
Document d'architecture complet
Téléchargez le document technique complet sur Dolutech SOC Model V1 — workflow de décision, contrôles de sécurité et flywheel d'apprentissage supervisé (PDF, anglais).


